�l���r�g�����ٷ���Ƽ�Փ���g�[��1��
ժ Ҫ�� ժ Ҫ���o�˙C�ďV�������ڽo���a�����������ͬ�r��Ҳ��������ȫ���������{���@����Ҫ���Ƿ��w�еğo�˙C�M��̽�y���R�e��Ȼ����С�o�˙C���w�eС�\���`�ʹ�Â��y�����_����늵�̽�y�ֶ��y�ԑ�������ˣ����һ�N���� YOLO(You only look once)v5 ��ȌW���W�j
����ժ Ҫ���o�˙C�ďV�������ڽo���a�����������ͬ�r��Ҳ��������ȫ���������{���@����Ҫ���Ƿ��w�еğo�˙C�M��̽�y���R�e��Ȼ����С�o�˙C���w�eС�\���`�ʹ�Â��y�����_����늵�̽�y�ֶ��y�ԑ�������ˣ����һ�N���� YOLO(You only look once)v5 ��ȌW���W�j��ܵ�С�o�˙C���r̽�y������ͨ�^�Ĕz�o�˙C�w���ˑB���������������M�И�ע���S�����Ô������� YOLOv5 �W�jģ���M��Ӗ�������yԇӖ��Ч����ͨ�^�������yԇ�W�jģ�����_�� 94.2%�ľ��_�ʡ�82.8%���ٻ��ʺ� 93.5%��ƽ�����Ⱦ�ֵ�����ģ�����挍�������M���˜yԇ��C��ҕ�l�������ʞ� 30 FPS(Frames Per Second)�l���£����� 30 �����Ȝʴ_�R�e�������ߴ�� 200 mm ���ϵğo�˙C���������^�õČ��r�ԡ�
�����P�I�~��Ŀ�˙z�y;YOLOv5;С�͟o�˙C;���r̽�y;��ȌW��
����1 ����
�����S���o��ͨ�š��w�п��ơ��T������������ҕ�l�����ȼ��g�Ŀ��ٰlչ����ǰС�͟o�˙C���g���죬��չʾ���ˏ���Ĺ��ܣ�ʹ���ڹ�����ȫ����Դ������r�Iֲ���ȶ�N�ИI�I�õ��ˏV�����á��S��С�����ßo�˙C�ijɱ������½���ُ�I�o�˙C�Đۺ��ߔ����B������[1]�������Ї��ֵĹٷ����������@ʾ������ 2020 ��ף��҇�������ӛ�o�˙C 52.36 �f�ܣ����w�����_�� 159.4 �fС�r��ͬ�������_ 27.5%[2]��Ȼ�����S��С�͟o�˙C�������I��ըʽ���L���O���y��Խ��Խ��, �䌦������ȫ�����ˇ������{���o���а��������˸�����������磬2021 �� 4 �� 3 �գ�����ʒɽ�C���l������o�˙C���w���¶�ܺ�����бP�����併�����C���İ���������Ӱ푺����������{�C����ȫ[3]����ˣ�ͨ�^���g�ֶΘ����o�˙C�O�yϵ�y�����Ƿ��w�еğo�˙C�M�о��_̽�y�c���ƣ����_����ҪĿ�˿���ȫ�����������ȫ����������Ҫ���x��
����Ŀǰ��������ᘌ��o�˙C̽�y�ij��ü��g��Ҫ�����_̽�y���W̽�y���o���̽�y�����̽�y��[4]������С�͟o�˙C�����w�eС���\���`������c�����y���ֶ��y��̽�y���С���w�������������R�e��o�˙C[5]����ˣ�С�͟o�˙C��̽�y��һ��ؽ����Q���y�}��
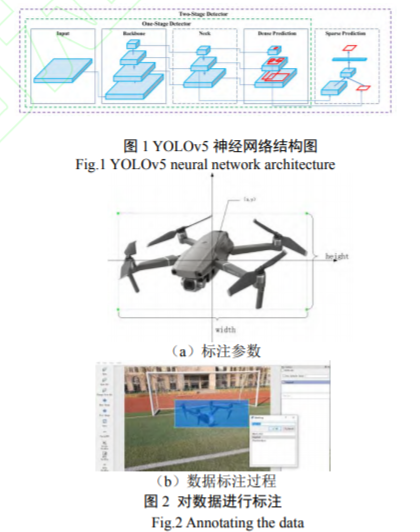
������������S����ȌW�����g���w�ٰlչ��������ȌW����Ŀ�˙z�y�㷨�nj��FС�o�˙C̽�y��һ�N�����ֶΡ�������ȌW����Ŀ�˙z�y�㷨��Ҫ��һ�A�z�y�����Ͷ��A�z�y�������һ�A�z�y��������Ҫ�Ϊ����Һ��x�^������ٶ��^�죬�� SSD(Single Shot MultiBox Detector) [6]��YOLO �ȡ����A�z�y�����t���z�y�㷨�փɲ��M�У���Ҫ�@ȡ���x�^���ٌ����M�з��������һ �� �� �� һ �A �� �� �� �� R-CNN ( Region-based Convolutional Neural Network)��Fast R-CNN [7]�ȡ��ڌ��H��������Ҫ���ɼ��ğo�˙Cҕ�l���M�Ќ��r̽�y�����A�㷨�y�ԝM�㌍�r��Ҫ�� YOLO ϵ���㷨��������µ����ܿ죬�������������ĜyԇЧ����Ҫ���� SSD �㷨[8]���������������˃ɷN���� SSD ���M�㷨�Č��r�o�˙C�R�e���������ɷN���M�������ȷքeֻ�� 79% �� 83.75%�������J��ԓ�㷨�R�e�ٶȻ����M�㌍�r��Ҫ��[9]���R���������˻��ڃ��� YOLOv3 �ĵͿ՟o�˙C�z�y�R�e���������Ú���W�j����߶��ںϵķ�ʽ��ԭʼ�� YOLOv3 �W�j�Y���M�Ѓ���������ͬӖ�����yԇ�� mAP ������ 8.29%���_�� 82.15%���z�y�ٶȞ� 26s-1���M�㌍�r��Ҫ��[10]�����ڵ�������˻��� YOLOv3 �ğo�˙C�R�e�c��λۙ�������� YOLOv3 ݔ��ҕ�l�еğo�˙Cλ����Ϣ������ PID �㷨�{���z���^�ǶȌ��F�o�˙C��λۙ��ģ���ڜyԇ�������_�� 83.24%�Ĝʴ_�ʺ� 88.15%���ٻ��ʣ��������Ӣ���_ 1060 �@����Ӌ��C�����_�� 20 ��ÿ����ٶ�[11]��YOLO �㷨�o�茦Ŀ�˺ͱ����M�Џ��s���˹���ģ�������^���������Σ��������������lչ�ܿ죬���R�e�ٶȺ��R�e�ʴ_�Է�����һ���ă��ݣ��ё����ڶ������������������g��������z�y[12]�����ڻ��̽�y[13]���ѳɞ�Ŀ�˙z�y���о����c��Ŀǰ YOLO �㷨�ѽ����µ�����汾 YOLOv5�����w�e�sС���sԭ���� 1/9���z�y�ٶȵõ�������������ȷ���Ҳ�в��e�ı��F����ˣ�����������õ���汾�� YOLO �㷨���F��С�͟o�˙C�Č��r̽�y�����ȣ����������Ĕz�ğo�˙C�w�Еr����Ƭ����������;��Σ����ȌW���h����ʹ�� YOLOv5 �p����ģ�͌��������M��Ӗ��;�����Ӗ���õ���ģ�͌�ҕ�l��DƬ�е�С�͟o�˙C�M��̽�y��
����2 YOLO v5 �㷨ԭ��
����YOLO �㷨������� Joseph Redmon ������ 2016 ���������һ�NĿ���R�e����[14]���䄓�������ڰљz�y�����ؚw���}̎����ֻ��һ�A�z�y����һ���W�j�Ϳɿ���ݔ��Ŀ��λ�úͷN������ă��ݾ���ͨ�^�������㷨���ԫ@�ó�ɫ���R�eЧ����Redmon ���㷨�M�и��M�����Ƴ��� YOLOv2[15]��YOLOv3 �ɂ��汾��Alexey Bochkovskiy �����Ƴ��� YOLOv4 �汾[16]���S�� YOLO �IJ�����µ��������㷨׃�ø�������_��Glenn Jocher �� 2020 ���Ƴ������°汾�� YOLOv5��YOLOv5 �汾�ǻ��� YOLOv4 �汾���M�ģ������� PyTorch ��ܴ����� YOLOv4 �汾�� Darknet ��ܣ��W�j����δ���ģ��H�������M���{��������ʹ�Ùz�y�ٶȴ�����������ęz�y�ٶ��_���� 140FPS[17];ͬ�r��YOLOv5 �љ����ļ����w�e�M���˿sС������ֻ�� YOLOv4 �� 1/9 ���ҡ�
����YOLO v5 �㷨�z�y�ɷ֞����������Ƚyһ�{���D��Ĵ�С���M�зָȻ���þ��e�W�j��ȡ���������ͨ�^�ǘO��ֵ����(Non-Maximum Suppression, NMS)�Y�x�؏��A�y��߅��ݔ����K���A�y�Y�����㷨�Ȍ����ЈD���M�гߴ��{����ݔ��D�֞� S×S �����ӣ���ͬ����ֻؓ؟�䌦���^������w�R�e���p�����دB�R�e�����p����Ӌ������ÿ�����ӕ��A�y��Ȳ��Ƿ����Ŀ�˵�λ���������ˣ���ij��Ŀ�˵�����λ����������ijһ�����ӣ���ôԓ���w���R�e�͕����@�����Ӂ�ؓ؟��ÿ��С���ӌ��A�y A ���ٶ�e�ĸ��ʺ� B ��߅���ÿ��߅������ 5 ���������քe�� x��y��w��h �� Confidence������(x, y)���A�y߅��������c����;(w, h)���A�y߅��Č��Ⱥ߶ȡ�Confidence ��ӳ߅�����Ƿ����Ŀ���Լ�����Ŀ�˕r�A�yĿ��λ�õĜʴ_�ԣ����ɹ�ʽ(1)Ӌ��õ���
����YOLOv5 Ŀ�˙z�yģ���ǻ��ھ��e�W�j���F�ģ���Ҫ��ݔ��ˡ�Backbone��Neck��Prediction �IJ��ֽM�� [14]���䘋����D 1 ��ʾ��ݔ��˲����� Mosaic ��������������СĿ�˵ęz�yЧ�������⣬�������m���^��Ӌ��ķ�������ͬ�Ĕ����������г�ʼ�O���L�����^���Եõ�����Ľ����ȣ���ߴ�������Ӗ�����A�y��Ч��;Backbone ���֞��ڲ�ͬ�D�������Ͼۺϲ��γɈD�������ľ��e�W�j����Ҫ�� Focus �Y���� CSP �Y���� Neck �������� Backbone �� Prediction ֮�g����һϵ�л�ϺͽM�ψD�������ľW�j�ӣ����D���������f�� Prediction ���֡�Prediction ���֞���K�z�y���֣���Ҫ���D�������M���A�y��������߅����A�yĿ�˷N�������� GIoU_loss(Generalized Intersection over Union)Ӌ���A�y��(predicted bounding box)�ؚw�pʧ������ֵ�� Box ֵԽС���A�y��ؚwԽ�ʴ_;������ BCE Logits_loss Ӌ��Ŀ�˙z�y�pʧ������ֵ��objectness ֵԽС��Ŀ�˙z�yԽ�ʴ_;���ö�Ԫ�����ؓpʧ���� BCE_loss Ӌ��Ŀ�˷�pʧ������ֵ, classification ֵԽС��Ŀ�˷��Խ�ʴ_��
����3 ̽�y���
����3.1 �������Ĝʂ�
����Ŀǰ��������ȌW����С�͟o�˙C̽�y�����о��^�٣����W�ϛ]�И˜ʵĔ������ɹ�ʹ�ã������Ҫ���вɼ������������蔵������
����(1)�����ɼ����ڲ�ͬ��⡢�r�g�ͱ���������o�˙C�M���Ĕz������̖�քe�� Inspire2(�ߴ�� 645mm×650mm×313mm ) �� Mavic Air2 (�ߴ�� 183mm×253mm×77mm ) �� Phantom4 pro (�ߴ�� 330mm×225mm×405mm)��������Æ��_ Inspire2 �DƬ 60 �������_ Mavic Air2 �DƬ 64 �������_ Phantom4 pro �DƬ 62 ����2 �_�����ϟo�˙C�DƬ 24 ����
����(2)������ע��YOLOv5 ģ��Ӗ��ǰ�茦�������M�И�ע���x�� LabelImg ��עܛ�����DƬ�еğo�˙C�M���˹���һ��ע���������x���o�˙C߅�粢��ע���Q����ע�^����D 2(a)��ʾ��ÿһ���DƬ��ע��֮�����Ԅ�����һ��������ע��ęn���������w���Q��̖��߅����λ�úʹ�С����Ϣ����D 2(b)��ʾ��
����(3)���������������DƬ�͌����Ę�ע�ļ��ς����C���W���Wվ roboflow.com �M�и�ʽ�����{�����؞� 640px�������� 7��2��1 �ı����քe�O��Ӗ��������C���͜yԇ����
����3.2 �W�jӖ��
�����W�jӖ�����ڌ�����ȌW��������ƽ�_���M�еģ�ƽ�_��Ӳ�����ú��_�l�h����� 1 ��ʾ��
��������^�̞錦С�͟o�˙C�������M���w�ƌW��Ӗ����Ӗ��ʹ�� YOLOv5s ���p�����AӖ��ģ�� yolo v5s.pt (ͨ�^ COCO val2017 ������Ӗ���õ����p�����z�yģ��)����֪�RԴ�M���w�ƌW������Ŀ�˷N��� nc (number of classes)�� 3�������������ļ� data.yaml ���O�úÔ�����·����ݔ��D��ߴ�� 640px��ǰ�������̎����С�O�Þ� 64�������Δ��O�Þ� 600�����^Ӗ�����õ�����С�͟o�˙C��������Ŀ�˙z�yģ�ͣ�ԓģ�Ϳ����ڙz�yҕ�l��ÿһ���D���еğo�˙C�����A�y�o�˙C��߅�����̖�����������Ŷȡ�
�������P֪�R���]���o�˙C�I��Փ����ΰl��
����ʹ�� Tensorboard ��ҕ�����߲鿴ģ��Ӗ���Y�����D3(a)��(b)��(c)�քe��Ӗ���^�����A�y��ؚw�pʧ������ֵ��Ŀ�˙z�y�pʧ������ֵ����pʧ������ֵ�S�����Δ���׃����r�����Կ��������N�pʧ������ֵ�S�����Δ������ӿ����½���Ӗ�����ڵ����� 500 ������څ�ڷ��������څ���Ք����D 4 ��ʾӖ���^���о��_�ʡ��ٻ����S�����Δ���׃����r���S�������Δ����ӣ����_�ʺ��ٻ��ʿ���������څ���ڷ������D 5 �鮔������ IoU �ֵ�քe�� 0.5 �� 0.5:0.95 �rƽ�����Ⱦ�ֵ(Mean Average Precision�����Q mAP)����������څ�ڷ�����
����3.3 ģ�͜yԇ
�����W�jӖ���Y���ќyԇ���еĈDƬݔ��Ӗ���õľW�jģ���M���R�eĿ�˵�λ�ûؚw��ֻ��ͬ�r�M�� IoU≥0.5���o�˙C�ķN��R�e���_�@�ɂ��l���r���ж��z�y�R�e���_;��t���e�`���xȡ���_��(Precision)���ٻ���(Recall)��ƽ�����Ⱦ�ֵ(mean Average Precision, mAP)�����u�rָ�ˣ����_�ʱ�ʾ�����б��z�y�����Ęӱ��Ќ��H�����ӱ��ĸ��ʣ��乫ʽ��(6)��ʾ;�ٻ��ʱ�ʾ�ڌ��H�����Ęӱ��б��z�y�����ӱ��ĸ��ʣ��乫ʽ��(7)��ʾ;ƽ�����Ⱦ�ֵ��ʾ�����Йz�ye�ϵ�ƽ�����ȵľ�ֵ���Ⱦ��_�ʺ��ٻ��ʸ��ܷ���ģ�͵�ȫ�����ܣ��乫ʽ��(8)��ʾ��
����4 ���Y���c����
����4.1 �������yԇ�Y������
�����Üyԇ�� 21 ���DƬ��Ӗ��ģ���M�Мyԇ���Y����� 2 ��ʾ���������� IoU ֵ�� 0.5 �r��Ӗ���õ���ģ���܉��_�� 94.2%�ľ��_�ʺ� 82.8%���ٻ��ʣ����N�o�˙C�R�e�ľ��ȷքe�飺Inspire2 �� 95.4%��Mavic Air2 �� 92.1%�� Phantom4 pro �� 95.2%���_�����^�ߵ��R�e���ȽY�����yԇ���в��֙z�y�Y����D 8 ��ʾ���ڶ�N�����¾��܉����_�ęz�y��Ŀ�˟o�˙C�����ʴ_�R�e������̖e������ͬ�ķ�����ƽ�_�ϣ�ʹ����ͬ�Ĕ������� YOLOv3 �� YOLOv5 �ɷN�㷨�M�Ќ��Ȝyԇ���Y����� 3 ��ʾ��ʹ�� YOLOv5 ģ���M�Мyԇ�r��mAP �_�� 93.5%���R�e�ٶ����_�� 141 FPS�����_���_�� 94.3%��YOLOv3 ģ�͵� mAP �� 81.5%���R�e�ٶȞ� 59 FPS�����_�ʞ� 83.2%�������Ĝyԇ�Y�����w��Ҳ�����īI[10]��[11] ���� YOLOv3 �㷨�Ĝyԇ�Y�����������īI[9]���õĸ��M�� SSD �㷨��
����4.2 �挍����̽�y
�������Mһ����C���� YOLOv5 ���o�˙C�Č��r̽�y�����������ͨ�^�Ĕzһ�Οo�˙Cҕ�l��ʹ��Ӗ���õ���ģ�͌����M��̽�y��ԓҕ�l��ͬ�r������� 3 �N�o�˙C�Į��棬ҕ�l�ֱ��ʞ� 19201080�������� 30 FPS���R�e�Y����D 9 ��ʾ�����^��o�˙C Inspire2 �ڼs 45 �����ȣ��^С�o�˙C Mavic Air2 �ڼs 30 �����ȣ�ԓģ�ͻ����ܙz�y��ҕ�l�еğo�˙CĿ�ˣ���̖�R�e�ʴ_��ͬ�r���Ŷ��^�ߡ�ÿһ���D����R�e�r�g�s�� 0.007 �룬�R�e�����h����Դҕ�l�����ʣ������^�õČ��r�ԡ�ͨ�^���ĵČ�������C YOLOv5 �㷨�ڟo�˙C���r̽�y�����ϵļ��g���ݡ�
����5 �YՓ
����(1)ʹ���w�ƌW��Ӗ����� YOLOv5 ģ���ڜyԇ�����܉��_�� 94.2%�ľ��_�ʡ�82.8%���ٻ��ʺ� 93.5%��ƽ�����Ⱦ�ֵ����ģ�Ͳ��H���R�e��С�͟o�˙C��߀���R�e������w��̖������ע�����Ŷȡ�
����(2)���挍�����£�ԓ�����܌���W�O���O���ҕ�l���M�Ќ��r̽�y�R�e������� NVIDIA GTX TITAN Xp 12 GB �@����Ӌ��C�����_�� 142 FPS ���ٶȣ��_���^���������R�eЧ����
�����mȻ��������ķ��������^�ã������ھ��x�^�h��С�͟o�˙C���R�eЧ�����ѡ���� YOLO ģ�͕����DƬ���s̎�������������Пo�˙CĿ���^�h(��ߴ��^С)�r�����s��o�˙C�����^С���o����ȡ��Ч���������y���R�e����һ�����]�����ӳ߶ȡ��W�j�z�y��֧�ȷ�ʽ�� YOLOv5 �㷨�M���ģ����߲�ȡ�ȷָ��D��С�D���ٙz�yС�D�ķ�ʽ����СĿ�˵�̽�y������——Փ�����ߣ������磬�x����������A�����ǘs������
���������īI��
����[1] GUVENCE I, KOOHIFAR F, SINGH S , et al. "Detection, Tracking, and Interdiction for Amateur Drones," in IEEE Communications Magazine, vol. 56, no. 4, pp. 75-81, April 2018, doi: 10.1109/MCOM.2018.1700455.
����[2] ��ޱ.�����_ͨ�ú��չ����I��С�M������ȫ�w�� �h [EB/OL]. http://www.caacnews.com.cn/1/1/202102/t20210226_1 320077.html, 2021-02-26.
����[3] �S��,����. ��ҹͻ�l!����ʒɽ�C���M���w�C����P��������o�˙C����!���ֺ����併�������Ϻ� [EB/OL]. https://hznews.hangzhou.com.cn/shehui/content/2021- 04/04/content_7940611_2.html, 2021-04-04.
����[4] �����,�f�|��,�x����.“����С”�o�˙C̽�y����[J]. ָ�]�����c����,2020,42(02):128-135. QU X T, ZHUANG D Y, XIE H B. Detection Methods for Low-Slow-Small(LSS) UAV[J]. Command Control & Simulation, 2020,42(02):128-135.